Introduction
Open Neuromorphic’s SNN frameworks guide currently counts 11 libraries, and those are only the most popular ones! As the sizes of spiking neural network models grow thanks to deep learning, optimization becomes more important for researchers and practitioners alike. Training SNNs is often slow, as the stateful networks are typically fed sequential inputs. Today’s most popular training method then is some form of backpropagation through time, whose time complexity scales with the number of time steps. We benchmark libraries that all take slightly different approaches on how to extend deep learning frameworks for gradient-based optimization of SNNs. We focus on the total time it takes to pass data forward and backward through the network as well as the memory required to do so. However, there are obviously other, non-tangible qualities of frameworks such as extensibility, quality of documentation, ease of install or support for neuromorphic hardware that we’re not going to try to capture here. In our benchmarks, we use a single fully-connected (linear) and a leaky integrate and fire (LIF) layer. The input data has batch size of 16, 500 time steps and n neurons.
Benchmark Results
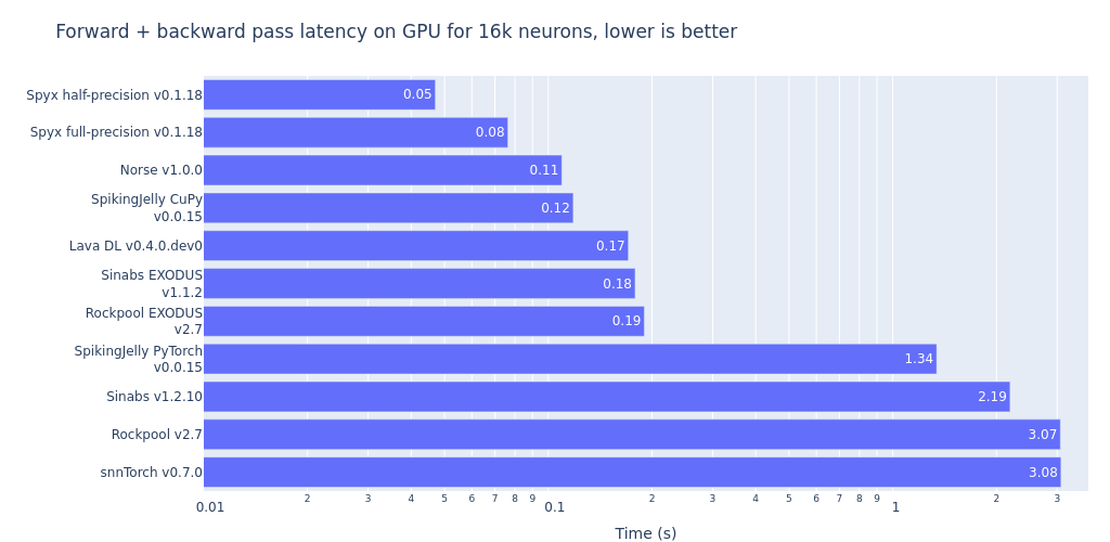
The first figure shows runtime results for a 16k neuron network. The SNN libraries evaluated can be broken into three categories: 1. frameworks with tailored/custom CUDA kernels, 2. frameworks that purely leverage PyTorch functionality, and 3. a library that uses JAX exclusively for acceleration. For the custom CUDA libraries, SpikingJelly with a CuPy backend clocks in at just 0.26s for both forward and backward call combined. The libraries that use an implementation of SLAYER (Lava DL) or EXODUS (Sinabs EXODUS / Rockpool EXODUS) benefit from custom CUDA code and vectorization across the time dimension in both forward and backward passes and come within 1.5-2x the latency. It is noteworthy that such custom implementations exist for specific neuron models (such as the LIF under test), but not for arbitrary neuron models. On top of that, custom CUDA/CuPy backend implementations need to be compiled and then it is up to the maintainer to test it on different systems. Networks that are implemented in SLAYER, EXODUS or SpikingJelly with a CuPy backend cannot be executed on a CPU (unless converted).
In contrast, frameworks such as snnTorch, Norse, Sinabs or Rockpool are very flexible when it comes to defining custom neuron models.
For some libraries, that flexibility comes at a cost of slower computation.
This is particularly true if the libraries are not built in a way that modern compiler techniques, such as the OpenAI Triton compiler, can exploit.
One such optimization was introduced in PyTorch 2.0 with torch.compile, which uses just-in-time (JIT) compilation to optimize the runtime instructions for specific platforms.
The main motivation for torch.compile is to provide high performance without having to write platform-tailored code such as CUDA kernels with downside that the models will take a few seconds to compile during runtime.
In our tests, torch.compile brought the performance of Norse models close to that of JAX/Spyx and SpikingJelly, but we did not observe significant speedups for snnTorch and Sinabs.
The performance gain for Norse can be explained by the library’s functional design where the state object that lends itself well to parallel execution and compilation.
SpikingJelly also supports a conventional PyTorch GPU backend with which it’s possible to define neuron models more flexibly. Such implementations are also much easier to maintain, as relying on the extensive testing of PyTorch means that it will likely work on a given machine configuration.
Striking a balance between flexibility/extensibility and efficiency from compilation, Spyx is a new framework for training SNNs within the JAX ecosystem. JAX is a high-performance array computing framework that provides autodifferentiation and Just-In-Time (JIT) compilation with a Numpy-like API and is developed and maintained by Google. By building on top of Google Deepmind’s JAX-based neural network library Haiku, Spyx implements a number of common neuron models as well as enables users to define their own, with the model forward passes, gradient calculations, and even entire training loops being able to be JIT compiled for execution on GPUs, TPUs, or on CPU. In the benchmark, computing using full precision (fp32) and half precision (fp16) achieve the fastest training loops.
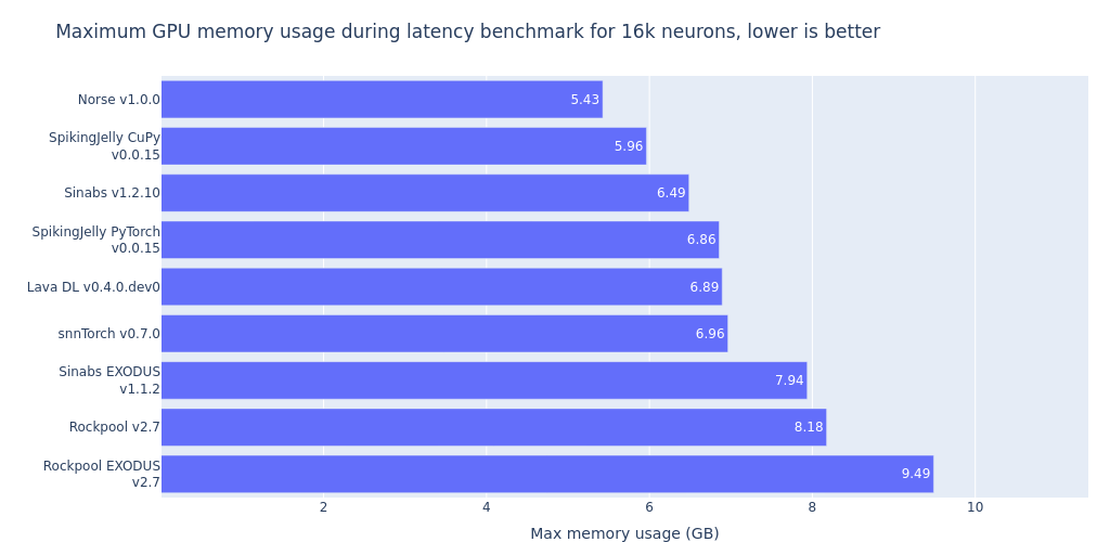
The second figure shows the maximum memory usage during forward and backward pass for the same networks. The compiled Norse model comes out on top, which is interesting because it is being built in pure Python.
This is most likely due to compiler techinques such as kernel fusion, where subsequent PyTorch layers are fused into single operations to avoid device bottleneck and to leverage the single instruction, multiple data (SIMD) architectures of GPUs.
The memory usage benchmarks were collected using PyTorch’s max_memory_allocated() function, unfortunately JAX does not have a similar function so for now Spyx is not included in the memory benchmark.
Summary
The ideal library will often depend on a multitude of factors, such as accessible documentation, usability of the API or pre-trained models. Generally speaking, PyTorch offers good support when custom neuron models (that have additional states, recurrence) are to be explored. For larger networks, it will likely pay off to rely on CUDA-accelerated existing implementations, or ensure your model is compatible with the recent compilation techniques to leverage the backend-specific JIT optimizations. The development of Spyx offers an interesting new framework as it enables the flexible neuron definitions of PyTorch frameworks while also enabling the speed of libraries which utilize custom CUDA backends. One more note on the accuracy of gradient computation: In order to speed up computation, some frameworks will approximate this calculation over time. Networks will still manage to learn in most cases, but EXODUS, correcting an approximation in SLAYER and therefore calculating gradients that are equivalent to BPTT, showed that it can make a substantial difference in certain experiments. So while speed is extremely important, other factors such as memory consumption and quality of gradient calculation matter as well.
Edits
13/08/2023: Sumit Bam Shrestha fixed Lava’s out-of-memory issue by deactivating quantization. That makes it one of the best performing frameworks.
22/10/2023: Kade Heckel reperformed experiments on an A100 and added his Spyx framework.
07/11/2023: Cameron Barker containerized the benchmark suite and added the memory utilization benchmark. The updated benchmarks were run on a RTX 3090 with a batchsize of 16.
19/2/2024: Jens E. Pedersen updated the benchmark for Norse to use the correct neuron model and torch.compile.
Code and comments
The code for this benchmark is available here. The order of dimensions in the input tensor and how it is fed to the respective models differs between libraries.
Benchmarks were run on a NVIDIA RTX 4090 with 24GB of VRAM. Frameworks use full precision computation unless stated otherwise.
Some things that would be interesting to add:
- multilayer scalability and benchmarking
- evaluation of PyTorch frameworks when using torch.compile and with automatic mixed precision
- ✔ Done for Norse
- check that forward dynamics are roughly equal in each case
- given equivalent forward dynamics, check gradient correlations and magnitudes
- ✔ memory consumption of different libraries
- ✔ add JAX framework
Enjoy this content? Share it!
Sharing our articles and resources is one of the easiest and most effective ways to support Open Neuromorphic. It helps us reach a wider audience, grow our community, and continue our mission of advancing open-source neuromorphic computing. Your support is greatly appreciated!

About the Authors

Gregor Lenz

Jens E. Pedersen
Have an idea? Share your voice.
Open Neuromorphic is a community-driven platform. We invite you to share your research, tutorials, or insights by writing a blog post.